The K-Nearest Neighbours (KNN) classifier is a nonparametric lazy classifier. In nonparametric classification the algorithm does not assume any specific distribution for the data sets. Lazy classifiers do not generalise the classification model and calculate the class of the item at the time of testing instead of training, which makes training very efficient by reducing the cost of testing time 1.
KNN estimates items’ classes according to their nearest neighbours. The majority of the K nearest neighbours decide the class of the input item. An odd number of for K is selected (between 3 to 9) to prevent ties. The nearest neighbours are decided using one of the distance measures (e.g. Euclidean distance), as shown in Figure \ref{fig:KNN} 2.
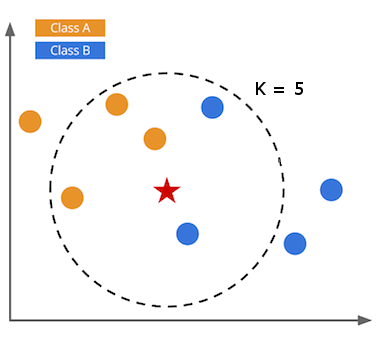
To prevent attribute bias due to different magnitudes of values it is strongly preferred to normalise all attributes before classification. Non-numerical attributes can also be used with KNN classification, similar attributes with the K neighbours have zero distance, and different attributes have the distance of 1 2.
While this classification algorithm is different from rule-based classifiers, we used a variation of this classification for temporal attributes, as explained in chapter six, as a comparison with our proposed classification algorithm to test the performance difference between the algorithms.
Reference
-
Wettschereck, D., Aha, D. W. and Mohri, T. (1997) ‘A Review and Empirical Evaluation of Feature Weighting Methods for a Class of Lazy Learning Algorithms’, Artificial Intelligence Review. Springer, 11(1–5), pp. 273–314. doi: 10.1023/A:1006593614256. ↩
-
Zaki, M. J. and Meira, M. J. (2014) Data Mining and Analysis: Fundamental Concepts and Algorithms, Cambridge University Press. New York: Cambridge University Press. ↩ ↩2