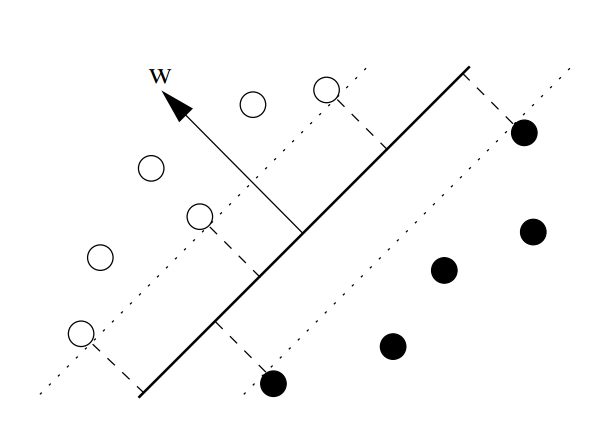
Support Vector Machine is a binary parametric classifier that classifies items by creating a hyperplane between classes. This algorithm tries to find an optimum position for the hyperplane so that it splits the classes with the maximum margin between class items and minimum empirical risk. The items on the edges of the margin are called support vectors, as each item can be seen as a vector. An example of an SVM classifier’s hyperplane is shown in Figure below. It can be noticed that in a two-dimensional data set the hyperplane is represented as a line 1.
One of the advantages of SVM is that it can use kernel trick. For a data set with nonlinear separation between classes, we can map the d-dimensional items xi of input space into a high-dimensional feature space using a nonlinear transformation function 2.
SVM has been used as an elementary stage to create rule-based classifiers. Nunez et al. 3 used rule extraction mechanism to extract rules from an SVM model generated via training samples. The rules are constructed using multiple of ellipsoid equations. While these rules might present a good visual illustration for the rules, especially for two-dimensional spaces, these equations have mathematical forms so that the generated rules are not intuitive and easy to understand as stand alone rules. Moreover, the ellipsoids are not one-to-one maps for the actual hyperplanes of SVM, so the rule-based classifiers are not as efficient as their SVM counterparts and they have a higher error rate.
Reference
-
Muller, K.-R. et al. (2001) ‘An introduction to kernel-based algorithms’, IEEE Transactions on Neural Networks, 12(2), pp. 181–202. ↩
-
Zaki, M. J. and Meira, M. J. (2014) Data Mining and Analysis: Fundamental Concepts and Algorithms, Cambridge University Press. New York: Cambridge University Press. ↩
-
Núñez, H., Angulo, C. and Català, A. (2006) ‘Rule-based learning systems for support vector machines’, Neural Processing Letters, 24(1), pp. 1–18. doi: 10.1007/s11063-006-9007-8. ↩