A rule-based classifier uses a set of rules to classify items in a data set. The rules are formalised in the form of IF-THEN clause. The conditions of the IF clause represent the rules that an item should fulfil to be accepted as a particular class. If the rules are ordered and have priority they can be represented in nested IF-THEN-ELSE clauses and might be called decision lists 1.
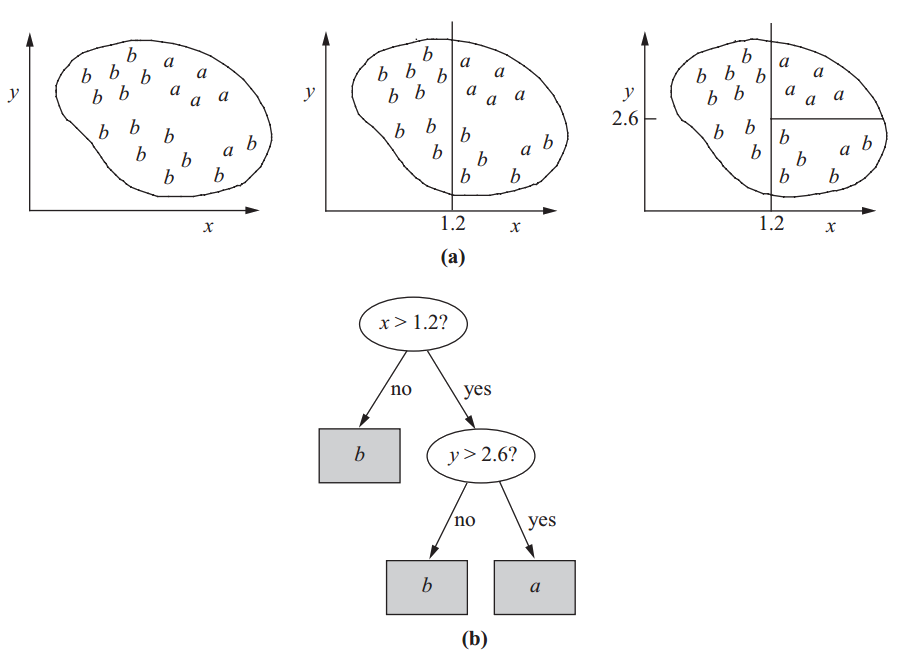
Figure below (a) shows a simple data set with items labelled a or b. We can produce multiple variations of rules to classify items in this data set. It is possible to filter out all class a items first then all others remaining will be class b: If x $>$ 1.4 and y $<$ 2.4 then class = a
Otherwise class = b
Conversely, if b class items are filtered out the remaining items will be classified as a: If x $\leqslant$ 1.2 then class = b
If x $>$ 1.2 and y $\leqslant$ 2.6 then class = b
Otherwise class = a
In most cases, rule-based classification systems and decision trees can be used interchangeably; C4.5 provides both decision trees and classification rules [^3]. A decision tree representing the rule-based classifier is shown in Figure below (b). The rules above and the decision tree can be considered as an equivalent classifiers, but most of the time people prefer rule-based classifiers on decision trees as they are more intuitive for human understanding 1, due to being simpler and more concise [^3].
Various methods are used to generate rule-based classifiers in different fields of application. The remainder of this section presents more effective samples of these works with a brief explanation of their methodologies.
Rodriguez et al. 2 used rule-based classification to classify power quality disturbances of signals. They used S-transform to extract features from signals, as this transform can generate variable window size with the ability to preserve phase information during decomposition 3. They used leaner and parabolic lines to separate between classes. The separation line is produced using a heuristic function to guarantee maximisation of the number of correctly classified signals from the provided training set.
Chung et al. 4 use a two-stage classification method to classify power line signals, in the first of which they used a rule-based classifier to differentiate interrupt signals from others, which were then further classified using Hidden Markov Model classifier. The rules of the first stage classifier are created by domain experts relying mainly on the IEEE standards for signal interruption conventions, thus this classifier does not require a training set, as it is a static set of rules that can be calculated directly.
McAulay et al. 5 used genetic algorithms to create rule-based systems to identify alphabetical numbers. The system uses a random rule generator to create initial rules, which are enhanced through multiple generations by adjusting the initial rules. However, they notice that genetic algorithms might override even good rules which can identify specific characters. To prevent overriding rules, they introduced the concept of remembering rules for a long time if they succeeded to identify the training set example correctly.
Orriols-Puig et al. 6 used an evolutionary algorithm to create a rule-based classification system in which the system initiates with a set of classifier rules, then evolves online with the environment (new training items) to produce an accurate classification model. They proved that their classification method outperforms other methods (including support vector machine) in classifying data sets with imbalanced class ratios.
Nozaki et al. 7 used fuzzy systems to create a rule-based classifier. Generating fuzzy rule-based classification system requires two phases, first partitioning the patron space into fuzzy subspaces and then defining a fuzzy rule for each of these. Nozaki et al. used a fuzzy grid introduced by Ishibuchi et al. [^15] with triangle-shaped membership function to generate fuzzy rules from fuzzy subspaces. To enhance the classification results they introduced two procedures, error correction-based learning and significant rule selection. Error correction-based process increases and decreases the procedure of increasing or decreasing rule certainty according to its classification of the items; if a particular rule correctly classified an item its certainty will increase, otherwise, it will decrease accordingly. Significant rule selection is a mechanism to prune unnecessary rules to construct a compact set of a fuzzy rule-based classifier.
As demonstrated above, many domains of computer science and machine learning are used to generate and optimise rule-based classification systems, including expert systems, genetic algorithms, evolutionary algorithms and fuzzy systems. While these classifiers are efficient and effective methods to classify underlying data sets, they require a training data set for rule generation and optimisation. This means a sufficient amount of correctly labelled samples should be available to cover all or most of the aspects and possibilities of situations and characteristics that have to be classified.
The availability of the training data set might not always be an option due to the fact that labelling items is a tedious and laborious undertaking requiring a extensive periods of professionals’ valuable time. Experts might know the general rules for classifying items but they cannot identify the attributes of the classes individually due to the complexity of the underlying data sets. Moreover, domain experts might not quite agree on the fine differences between classes, so that it is hard to have a general single view for classifying items in the data set (such as in public goods games case study).
After the training stage these methods create a list of rules that represent the final rule-based classifier model, which might not cover all different opinions for nuanced cases of the classification (i.e. after the training stage, the classifier might lack the required generalisation). As noted previously, the generalisation problem might be solved by using rule pruning 7. However, this generalisation can be called local, as it depends on the training data, which is probably classified and labelled using expert single views.
Another aspect which is lacking in the presented methods is that they do not consider the classification of temporal data sets, as demonstrated in later sections. However, these methods also require training samples.
Reference
-
Witten, I. H., Frank, E. and Hall, M. a. (2011) Data Mining: Practical Machine Learning Tools and Techniques, Third Edition. Morgan Kaufmann. doi: 10.1002/1521-3773(20010316)40:6<9823::AID-ANIE9823>3.3.CO;2-C. ↩ ↩2
-
Rodriguez, A. et al. (2012) ‘Rule-based classification of power quality disturbances using S-transform’, Electric Power Systems Research, 86, pp. 113–121. doi: 10.1016/j.epsr.2011.12.009. ↩
-
Chen, C. S. (1996) ‘Statistical analysis of space-varying morphological openings with flat structuring elements’, IEEE Transactions on Signal Processing, 44(4), pp. 998–1001. ↩
-
Chung, J. et al. (2002) ‘Power disturbance classifier using a rule-based method and wavelet packet-based hidden Markov model’, IEEE Transactions on Power Delivery, 17(1), pp. 233–241. ↩
-
McAulay, A. D. and Oh, J. C. (1994) ‘Improving Learning of Genetic Rule-Based Classifier’, IEEE Transactions on Systems, Man, and Cybernetics. IEEE, 24, pp. 152–159. ↩
-
Orriols-Puig, A. and Bernadó-Mansilla, E. (2009) ‘Evolutionary rule-based systems for imbalanced data sets’, Soft Computing, 13(3), pp. 213–225. doi: 10.1007/s00500-008-0319-7. ↩
-
Nozaki, K., Ishibuchi, H. and Tanaka, H. (1996) ‘Adaptive fuzzy rule-based classification systems’, IEEE Transactions on Fuzzy Systems, 4(3), pp. 238–250. doi: 10.1109/91.531768. ↩ ↩2