External criteria validate the results of clustering based on some predefined structures of the data which is provided from an external source. The most well-known example of structural information is labels for the data provided by experts (called true classes). The main task of this approach is to determine a statistical measure for the similarity or dissimilarity between obtained clusters and labels 12. According to the methods incorporated in the external criteria, they can be divided into three types: pairwise measures, entropy-based measures and matching based measures 3.
As mentioned previously, the four types of classification guesses evaluation are true positive, true negative, false positive and false negative. These terms are used in the terminology of external cluster validity, especially when using pairwise measures, but with slightly different meanings to enable the evaluation of clusters in the same manner as classification 3:
- True Positives TP: Any two instances with the same label that are in the same cluster.
- False Negatives FN: Any two instances with the same label that are not in the same cluster.
- False Positives FP: Any two instances with different labels that are not in the same cluster.
- True Negatives TN: Any two instances with different labels that are not in the same cluster.
In this thesis, we use various external cluster validity indices to determine differences between a reference of behaviour for items in a temporal data and clusters of items in each time point. The method is discussed in more detail in chapter three and implemented in chapter four for public goods games and chapter six for stock market data. The used criteria in the thesis are listed below:
Jaccard Coefficient
This coefficient is a pairwise measure representing the degree of similarity between clusters. With this coefficient, each cluster is treated as a mathematical set, and the coefficient value is calculated by dividing the cardinality of the intersection of the resultant cluster with the prior cluster to the cardinality of the union between them 4:
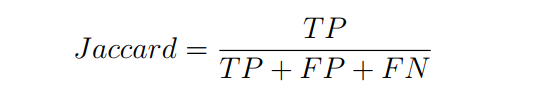
With a perfect clustering, when false positives and false negative equal to zero, the Jaccard coefficient value equals 1. This measure ignores the true negatives and only focuses on the true positives to evaluate the quality of the clusters 3.
Rand Statistic
The Rand statistic measures the fraction of true positives and true negatives over all point pairs; it is defined as
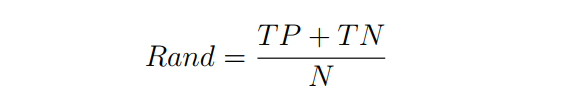
Where N is the total number of instances in the data set. This measure is similar to Jaccard Coefficient, so its value equals 1 in perfect clustering 3.
Fowlkes-Mallows (FM) Measure
FM define precision and recall values for produced clusters 5
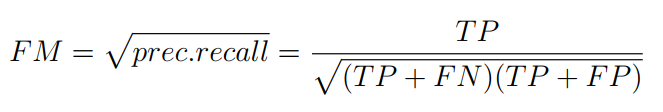
Where prec = TP/(TP + FP) and recall = P/(TP + FN). For the perfect clustering this measure equals 1 too 3.
Variation of Information VI
This index measure is based on contingency table which is a matrix with r × k_ , where r is number of produced clusters and k is the number of externally provided clusters. Each element of this matrix contains a number of agreed instances between any two clusters of the externally provided and produced clusters. As introduced by Meila 6, this index calculates mutual information and entropy between previously provided and produced clusters derived from the contingency table
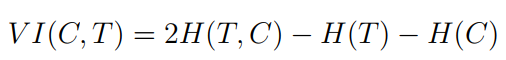
Where C is produced clusters, T is ground truth clusters, H(C) is entropy of C and H(T) is entropy of T 3.
Reference
-
Halkidi, M., Batistakis, Y. and Vazirgiannis, M. (2002) ‘Cluster validity methods: part I’, ACM Sigmod Record, 31(2), pp. 40–45. ↩
-
Rendón, E. and Abundez, I. (2011) ‘Internal versus External cluster validation indexes’, International Journal of computers and communications, 5(1), pp. 27–34. ↩
-
Zaki, M. J. and Meira, M. J. (2014) Data Mining and Analysis: Fundamental Concepts and Algorithms, Cambridge University Press. New York: Cambridge University Press. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Vendramin, L., Campello, R. J. and Hruschka, E. R. (2010) ‘Relative clustering validity criteria: A comparative overview’, Statistical Analysis and Data Mining, 4(3), pp. 209–235. doi: 10.1002/sam. ↩
-
Fowlkes, E. and Mallows, C. (1983) ‘A method for comparing two hierarchical clusterings’, Journal of the American …, 78(383), pp. 553–569. ↩
-
Meilă, M. (2007) ‘Comparing clusterings—an information based distance’, Journal of Multivariate Analysis, 98(5), pp. 873–895. doi: 10.1016/j.jmva.2006.11.013. ↩