Internal criteria measure the ‘goodness’ of clusters for the data by extracting information from data and clusters alone, such as the compactness of data points inside one cluster and the separation of clusters from each other 1. These criteria were used as part of the cost function, to determine the quality of the selected classification rules in each time point, and to compare different clustering algorithms’ performances, as presented in chapter six.
Dunn Index
This index calculates the ratio of minimum distance between clusters to the maximum distance between any two instances of the same cluster 2:
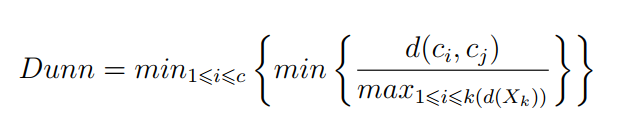
Where ci, cj ∈ c of size m and the maximum distance can be computed from the mean or between all pairs. A larger value for Dunn index means, better clustering output, because it means that the closest instances between two clusters are larger than the distance between two farthest instances in the same cluster 3.
Davies-Bouldin Index
This measure is introduced by Davies et al. 4. It calculates internal cluster compactness and inter cluster separation by producing the ratio of spreading sample points around mean (i.e. variation) to the distance between mean of clusters 1.
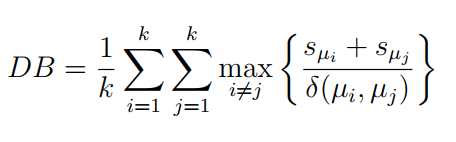
Where k is number of clusters, sμi and sμj are the spread of points around any two clusters cluster mean “Centroid”, and δ(μi, μi) denotes the mean of both clusters.
A smaller value of this measure indicates better the clustering, as in such cases the clusters are well separated and each cluster is well represented by its mean; in other words, larger values mean better compacted instances in the clusters and clusters that are well separated from each other 3.
SD
This measure is introduced by Halkidi et al. 5. It calculates the average scattering for clustering and total separation among clusters.
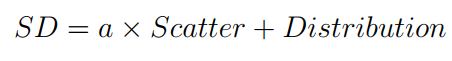
Where a is a weighting factor equal to the maximum distance of two instances in the data set. The Scatter indicates the average compactness of clusters. A smaller value of Scatter is a signal for a compact cluster, and its the value increases for less compact clusters. The Distribution is the measure of the total separation between clusters. A larger value Scatter indicates better clustering and a smaller value of this term indicates greater proximity between clusters to each other. Scatter, and Distribution have different ranges so that a (the weighting factor) is important to maintain the balance between them. As SD measure is a total of Scatterer and Distribution so that the smaller SD value indicates better clustering 5.
sdwb
This measure is introduced by Halkidi et al. 6. The S_Dbw index is similar to SD index as it measures the intracluster and intercluster variances 1. The definition of S_Dbw indicates that both criteria of “good” clustering (i.e. compactness and separation) are properly combined, enabling reliable evaluation of clustering results.
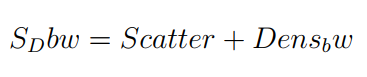
As with SD, the Scatter indicates the average compactness of clusters, smaller Scatter value indicating a compact cluster, with an increased value for less compact clusters. Dens_bw(c) indicates the inter-cluster density by calculating the average number of points between the clusters in relation with density within clusters. Thus a small value of Dens_bw means good separation among clusters. As in SD, a smaller value of this measure is an indication of well defined clustering 6.
Reference
-
Rendón, E. and Abundez, I. (2011) ‘Internal versus External cluster validation indexes’, International Journal of computers and communications, 5(1), pp. 27–34. available at: http://w.naun.org/multimedia/UPress/cc/20-463.pdf (Accessed: 7 April 2013). ↩ ↩2 ↩3
-
Dunn, J. C. (1973) ‘A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters’, Journal of Cybernetics, 3(3), pp. 32–57. doi: 10.1080/01969727308546046. ↩
-
Zaki, M. J. and Meira, M. J. (2014) Data Mining and Analysis: Fundamental Concepts and Algorithms, Cambridge University Press. New York: Cambridge University Press. ↩ ↩2
-
Davies, D. L. and Bouldin, D. W. (1979) ‘A cluster separation measure’, IEEE transactions on pattern analysis and machine intelligence, 1(2), pp. 224–227. doi: 10.1109/TPAMI.1979.4766909. ↩
-
Halkidi, M., Vazirgiannis, M. and Batistakis, Y. (2000) ‘Quality scheme assessment in the clustering process’, Principles of Data Mining and Knowledge Discovery, pp. 265–276. ↩ ↩2
-
Halkidi, M., Vazirgiannis, M. and Batistakis, Y. (2000) ‘Quality scheme assessment in the clustering process’, Principles of Data Mining and Knowledge Discovery, pp. 265–276. ↩ ↩2
Polla Fattah